4.7. Prilagodba funkcije podacima¶
Često je potrebno neke podatke dobivene npr. mjerenjima grafički prikazati i približno opisati nekom funkcijom (tzv. prilagodba ili “fitanje”).
from scipy import *
import numpy as np
import matplotlib.pyplot as plt
data = np.array([[0.2, 0.1], [0.35, 0.2], [1, 0.6], [1.8, 0.9], [2.5, 1.3], [4, 2.06], [5, 2.6]])
x = data[:, 0]
y = data[:, 1]
plt.scatter(x, y)
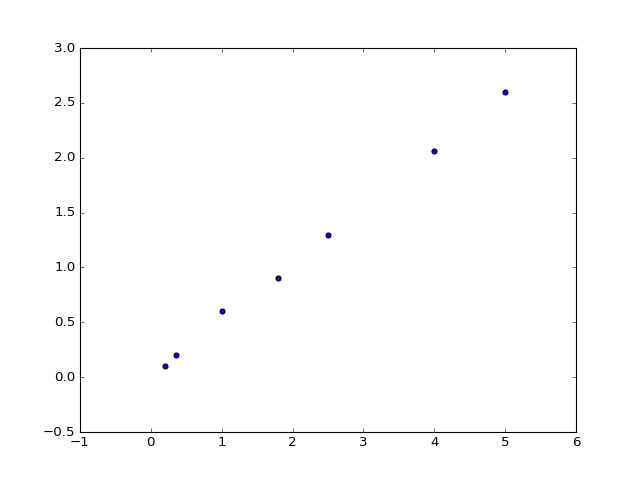
Klasična situacija je potreba za prilagodbom pravca \(f(x) = a + b x\) metodom najmanjih kvadrata (linearna regresija). Pogledajmo prvo kako bismo sami implementirali standardne formule za metodu najmanjih kvadrata:
>>> from scipy import *
>>> import numpy as np
>>> data = np.array([[0.2, 0.1], [0.35, 0.2], [1, 0.6], [1.8, 0.9], [2.5, 1.3], [4, 2.06], [5, 2.6]])
>>> x = data[:, 0]
>>> y = data[:, 1]
>>> n = len(data)
>>> n = len(data)
>>> delc = n*(x**2).sum() - x.sum()**2
>>> b = (n*(x*y).sum()-x.sum()*y.sum())/delc
>>> a = ((x**2).sum()*y.sum()-x.sum()*(x*y).sum())/delc
>>> sigsq = ((y-b*x-a)**2).sum()/(n-2)
>>> erra = sqrt((x**2).sum()*sigsq/delc)
>>> errb = sqrt(n*sigsq/delc)
>>> print("a = {:.3f} +/- {:.3f}".format(a, erra))
a = 0.020 +/- 0.023
>>> print("b = {:.3f} +/- {:.3f}".format(b, errb))
b = 0.513 +/- 0.008
Paket scipy.optimize sadrži funkciju curve_fit koja radi otprilike to isto, ali
je općenitija u smislu da krivulja koju prilagođavamo može biti
zadana bilo kojim matematičkim izrazom. Pogledajmo prvo
prilagodbu pravca. Prvo je potrebno definirati odgovarajuću Python funkciju:
>>> def model(x, a, b):
... return a + b*x
>>> from scipy.optimize import curve_fit
>>> pars, cov = curve_fit(model, x, y)
>>> pars
array([ 0.02015952, 0.51305612])
Funkcija curve_fit vraća dva objekta: vektor s numeričkim vrijednostima
parametara dobivenih prilagodbom i matricu kovarijanci. Za nas je dovoljno
znati da dijagonala te matrice sadrži kvadrat neodređenosti (varijancu)
parametara. Tako vrijednosti i neodređenosti parametara možemo ispisati
npr. ovako:
>>> for k, par in enumerate(['a', 'b']):
... print('{} = {:.3f} +/- {:.3f}'.format(par, pars[k], sqrt(cov[k,k])))
a = 0.020 +/- 0.023
b = 0.513 +/- 0.008
Vidimo da se rezultat slaže s gornjim. Nacrtajmo prilagođeni pravac zajedno s podacima:
from scipy.optimize import curve_fit
def model(x, a, b):
return a + b*x
pars, cov = curve_fit(model, x, y)
plt.plot(x, model(x, *pars))
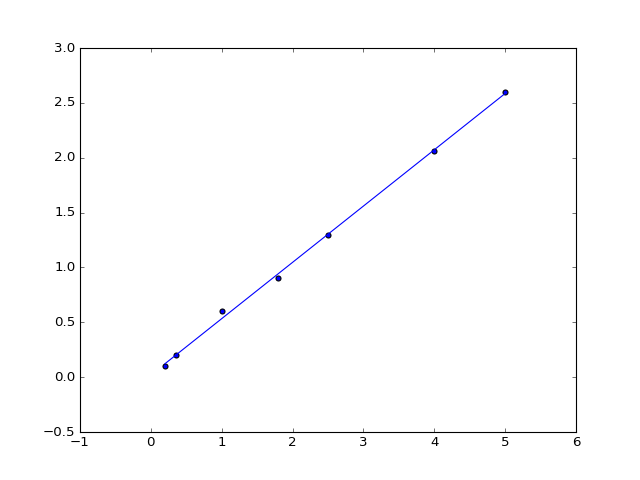
Možemo se sad zapitati da li je linearni model tj. pravac dovoljan ili ima smisla dodati još i kvadratni član. U tom slučaju prilagodba izgleda ovako:
>>> def model(x, a, b, c):
... return a + b*x + c*x**2
>>> pars, cov = curve_fit(model, x, y)
>>> for k, par in enumerate(['a', 'b', 'c']):
... print('{} = {:.3f} +/- {:.3f}'.format(par, pars[k], sqrt(cov[k,k])))
a = 0.027 +/- 0.035
b = 0.502 +/- 0.037
c = 0.002 +/- 0.007
Činjenica da je neodređenost paramera c znatno veća od vrijednosti samog
parametra, sugerira da je kvadratni član suvišan. (Štoviše, vidimo da je i
slobodni član a od malog značaja.)
Zadatak 1
Donjim podacima iz liste data2 prilagodite polinom trećeg reda, te funkciju
\(f(x)=a \sin(x)\) te nacrtajte sve na jednom grafu. Radi lakšeg
snalaženja neka krivulje budu različitih boja. Izračunajte zbroj
kvadrata odstupanja \(\sum_i (y_i - f(x_i))^2\) za oba slučaja.
Razmislite koji model je bolja “teorija” koja objašnjava dane eksperimentalne
podatke.
>>> data2 = np.array([[0, 0.1], [0.3, 0.4], [1, 0.7], [1.8, 1], [2.5, 0.5], [4, -0.6], [5, -1.0]])